
DreamID: A Fast and High-Fidelity diffusion-based Face Swapping via Triplet ID Group Learning













































































Abstract
In this paper, we introduce DreamID, a diffusion-based face swapping model that achieves high levels of ID similarity, attribute preservation, image fidelity, and fast inference speed. Unlike the typical face swapping training process, which often relies on implicit supervision and struggles to achieve satisfactory results. DreamID establishes explicit supervision for face swapping by constructing Triplet ID Group data, significantly enhancing identity similarity and attribute preservation. The iterative nature of diffusion models poses challenges for utilizing efficient image-space loss functions, as performing time-consuming multi-step sampling to obtain the generated image during training is impractical. To address this issue, we leverage the accelerated diffusion model SD Turbo, reducing the inference steps to a single iteration, enabling efficient pixel-level end-to-end training with explicit Triplet ID Group supervision. Additionally, we propose an improved diffusion-based model architecture comprising SwapNet, FaceNet, and ID Adapter. This robust architecture fully unlocks the power of the Triplet ID Group explicit supervision. Finally, to further extend our method, we explicitly modify the Triplet ID Group data during training to fine-tune and preserve specific attributes, such as glasses and face shape. Extensive experiments demonstrate that DreamID outperforms state-of-the-art methods in terms of identity similarity, pose and expression preservation, and image fidelity. Overall, DreamID achieves high-quality face swapping results at 512×512 resolution in just 0.6 seconds and performs exceptionally well in challenging scenarios such as complex lighting, large angles, and occlusions.
How does it work?
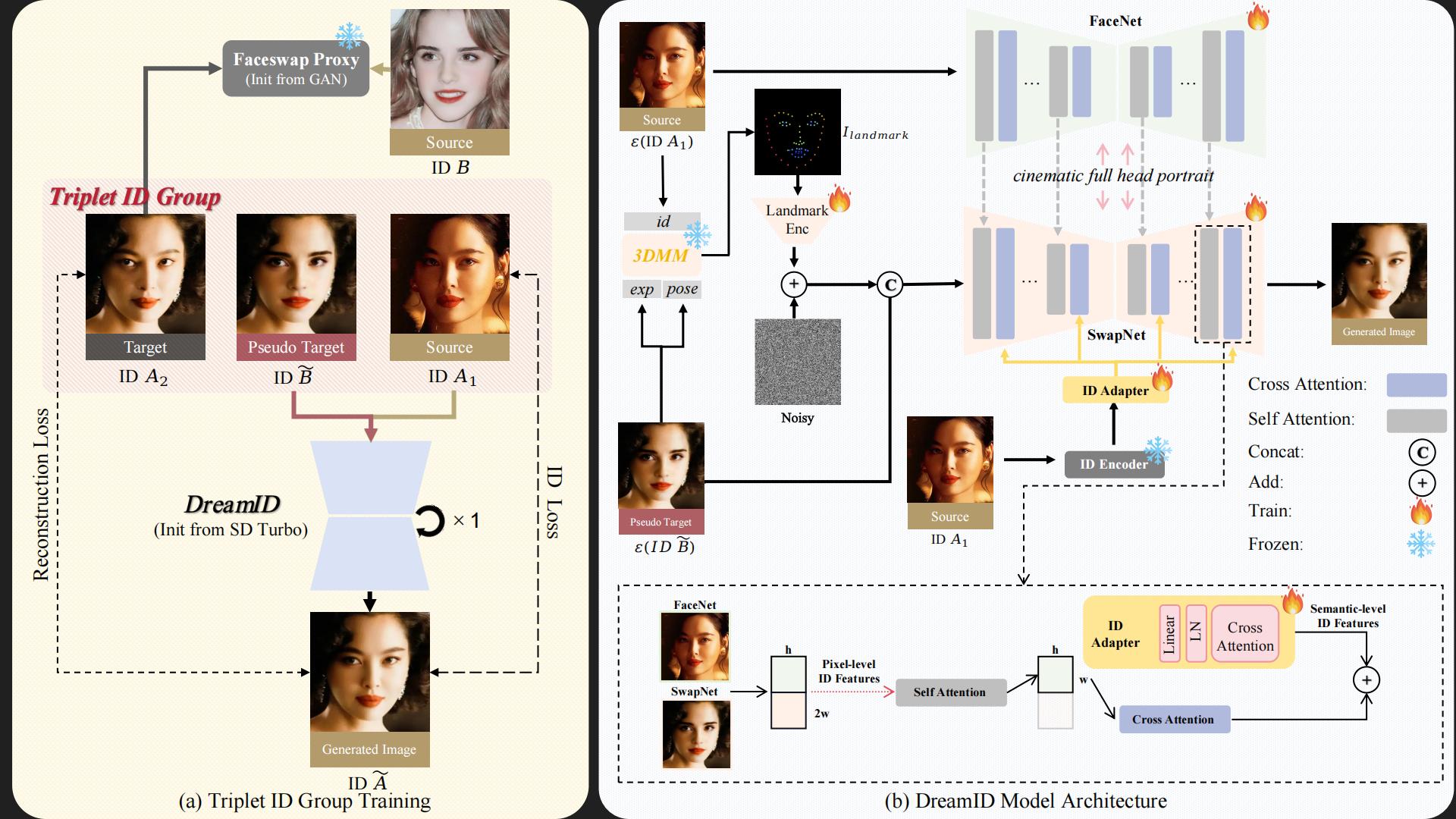
Overview of DreamID. (a)Triplet ID Group Training. We establish explicit supervision for face swapping by constructing Triplet ID Group data. The construction process utilizes two images with the same ID(A1 , A2) and one image with a different IDB, along with a FaceSwap Proxy model, to generate a Pseudo Target ID\( \tilde{B} \). Additionally, we initialize our DreamID with SD Turbo, reducing the inference steps to a single step. This allows for convenient computation of image-space losses, such as ID Loss and reconstruction Loss. (b) DreamID Model architecture. Our model architecture is composed of three components: 1) The base Unet, which we refer to as SwapNet, is responsible for the main process of face swapping. 2) the face Unet feature encoder, named FaceNet, which extracts pixel-level ID information of the user image. 3) the ID Adapter that extracts the semantic-level ID information of the user image. The core feature fusion computation process is illustrated at the bottom.
The capabilities of DreamID

DreamID achieves high-fidelity face swapping with unprecedented identity similarity—to our knowledge, it currently ranks as the most identity-preserving face-swapping model. It addresses long-standing challenges in the field, such as facial shape deformation, while excelling in attribute preservation (e.g., makeup, lighting) at a fine-grained level. Moreover, DreamID demonstrates robust performance under occlusions and extreme head poses.
Applications



DreamID performs well in stylized scenarios, including target images that are sketches or watercolors. It also handles 3D and cartoon target images effectively. Moreover, it excels not only with stylized target images but also with stylized user images.







DreamID has a wide range of applications across various scenarios, such as film and television scenes, ID portraits, magazine covers.




DreamID can also be used in multi-person scenarios, enabling a variety of interesting group photos.
Disclaimer and Licenses
The images used on this website and related demos are sourced from consented subjects or generated by the models. These pictures are intended solely to showcase the capabilities of our research. If you have any concerns, please feel free to contact us, and we will promptly remove any inappropriate content. Email:yefulong@bytedance.com
This research aims to positively impact the field of Generative AI. Any usage of this method must be responsible and comply with local laws. The developers do not assume any responsibility for any potential misuse.
Acknowledgments
We sincerely acknowledge the insightful discussions from Mengtian Li, Cenya Wu, Jizheng Ding and Liuxi Tao. We would like to thank Nanjiang Xie and Kaijun Chen for their contributions to the engineering deployment. We genuinely appreciate the help from Siying Chen, Qingyang Li, and Wei Han with the evaluation. Additionally, we would like to give thanks to InfiniteYou for providing the website template.
Citation BibTeX
If you find DreamID useful for your research or applications, please cite our paper:
@misc{ye2025dreamidhighfidelityfastdiffusionbased,
title={DreamID: High-Fidelity and Fast diffusion-based Face Swapping via Triplet ID Group Learning},
author={Fulong Ye and Miao Hua and Pengze Zhang and Xinghui Li and Qichao Sun and Songtao Zhao and Qian He and Xinglong Wu},
year={2025},
eprint={2504.14509},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.14509},
}